fortranでMonte Carlo Simulation→
HBOOKで出力→ANAPAWで解析のまとめ
要は卒論で行ったことのまとめ。初心者には役立つかもしれない。
Mersenne Twister
fortran 標準の rand は実行速度が遅く周期が短くて役立たずなので Mersenne Twister を導入する。 ここでは上記リンク先の「さまざまなバージョン・いろいろな言語での実装など」 > 「FORTRAN」 > mt19937.f を用いる。自分の環境ではそのままではうまく動かなかったので以下の点を改変。
- program main の部分を全て削除。mt19937.f を subroutine として用いる。
- 102行目
parameter(UMASK = -2147483648)の部分の数値をparameter(UMASK = -2147483647)へと変更。多分問題ないはず。
1
2
3
4
5
6
7
2
3
4
5
6
7
subroutine mtcalc(single)
double precision double
real single
double = grnd()
single = real(double)
return
end
以上の準備をした上でプログラムのメイン部分で例えば以下のように記述することで x に [0,100] の一様乱数が出力される。
double precision double
real single
double = grnd()
single = real(double)
return
end
1
2
3
4
5
6
7
8
9
10
11
2
3
4
5
6
7
8
9
10
11
implicit none
real x
integer i
c
call sgrnd(12345678)
c
do i=1,1000
call mtcalc(x)
x = x * 100
enddo
end
sgrnd()で乱数を初期化。()内の数字は何でも良い。前述の mtcalc により単精度の [0,1] 一様乱数を出力。
real x
integer i
c
call sgrnd(12345678)
c
do i=1,1000
call mtcalc(x)
x = x * 100
enddo
end
HBOOK
ヒストグラムを出力するため Cern library の HBOOK を利用する。Makefile中でCernlibをリンクする。オプションとして
-lpacklib -lnsl -lmathlib
あたりを追加。
全体の流れを示す為サンプル(sample.f)を示す。これは単に一様乱数を出力するだけなので面白味は無い。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
implicit none
real x,y,H
integer i,nevent
data nevent/100000/
c
common/pawc/H(1000000)
call Hlimit(1000000)
c
call Hbook1(1,'1d Histogram',200,0.,200.,0.)
call Hbook2(2,'2d Histogram',200,0.,200.,300,0.,300.,0.)
c
call sgrnd(12345678)
c
do i=1,nevent
call mtcalc(x)
x = x * 100
call mtcalc(y)
y = y * 200
call HF1(1,x,1.)
call HF2(2,x,y,1.)
enddo
c
call Hrput(0,'sample.hbk','N')
c
end
HBOOKのサブルーチンについてはHBOOKのsubroutineにまとめた。
real x,y,H
integer i,nevent
data nevent/100000/
c
common/pawc/H(1000000)
call Hlimit(1000000)
c
call Hbook1(1,'1d Histogram',200,0.,200.,0.)
call Hbook2(2,'2d Histogram',200,0.,200.,300,0.,300.,0.)
c
call sgrnd(12345678)
c
do i=1,nevent
call mtcalc(x)
x = x * 100
call mtcalc(y)
y = y * 200
call HF1(1,x,1.)
call HF2(2,x,y,1.)
enddo
c
call Hrput(0,'sample.hbk','N')
c
end
IDの応用
前述のIDの定義の仕方ではあまり芸が無い。 特に数が多くなったとき面倒。
1
2
3
4
5
6
7
8
9
10
11
12
13
2
3
4
5
6
7
8
9
10
11
12
13
implicit none
real x
integer i,labelint(10),HistoID(10)
character*20 labelchara(10),HistoTitle(10)
c
do i=1,10
labelint(i)=100+i
enddo
write(labelchara,10) labelint
10 format(i3)
c
HistoID=labelint
HistoTitle='Title '//labelchara
上記のように配列を使ってIDとタイトルを定義すると楽。この定義の上で
real x
integer i,labelint(10),HistoID(10)
character*20 labelchara(10),HistoTitle(10)
c
do i=1,10
labelint(i)=100+i
enddo
write(labelchara,10) labelint
10 format(i3)
c
HistoID=labelint
HistoTitle='Title '//labelchara
do i=1,10
call Hbook1(HistoID(i),HistoTitle(i),100,0.,100.,0.)
enddo
によりヒストグラムを定義し、iによる場合分けを行った上で
call Hbook1(HistoID(i),HistoTitle(i),100,0.,100.,0.)
enddo
call HF1(HistoID(i),x,1.)
で値を代入すれば良い。
ANAPAW
出力されたhbkファイルをANAPAWを用いて解析する(だが、実際にはPAWの機能しか使っていない)。 まず、ANAPAWを実行するディレクトリへhbkファイルを移動する。以下、ANAPAWのワーキングディレクトリのサブディレクトリhbk/ に sample.hbk があるものとする。ANAPAW起動後、
fetch hbk/sample.hbk
でhbkファイルを読み込む。ヒストグラム数が多くメモリが足りない時は
***** ERROR in HRIN : Not enough space in memory :
なるエラーが出る。この場合、
vmem 128
でビデオメモリを128MBまで増やしておくことで(デフォルトは10MB)、エラーを回避できる可能性がある。128MB以上はこのコマンドでは増やせない。
i
で読み込んだhbkファイルのヒストグラムIDとタイトルの一覧を表示。
ht ID
でIDのヒストグラムをプロット。他、PAWのコマンドは
PAW Reference manual
参照。日本語では
PAWコマンド表,
PAW Manual,
PAW 備忘録
が参考になる。
先のsample.hbkを読み込んで
zone 2 1
ht 1
ht 2 colz
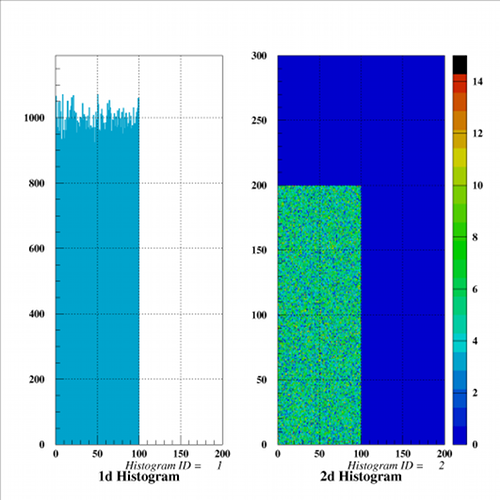
と打てば以下のような出力を得る。
ht 1
ht 2 colz
kumac
kumacはPAWのマクロ。 小林氏のページが参考になる。
以下、ヒストグラム(ID)をeps形式で保存するくだらないマクロ。
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
macro gh [1] [2]
*
for/file 66 [2].eps
gra/meta 66 -113
ht [1] colz
close 66
*
return
上のファイルを
gh.kumacとしてANAPAWのワーキングディレクトリにおいておき、
*
for/file 66 [2].eps
gra/meta 66 -113
ht [1] colz
close 66
*
return
exec gh ID FILENAME
とすれば、ヒストグラム(ID)をプロットしたFILENAME.epsというepsファイルが作られる。もっと真面目にepsを作りたければkumacファイルにコマンドを書いておけば良い。
PAWからテキストファイルを出力する
PAWではコマンドの先頭にshとつけておけばシェルのコマンドが使える。 よってPAWからテキストファイルを出力するには以下のような方法が使える。
sh echo "Hello world" >> test.dat
sh echo "test" >> test.dat
確認してみると
sh echo "test" >> test.dat
sh less test.dat
Hello world
test
ちゃんとテキストファイルが作成されている。kumacなら以下のように書くほうが色々汎用的になる。
Hello world
test
filename = test.dat
sh echo "Hello world" >> [filename]
sh echo "test" >> [filename]
sh echo "Hello world" >> [filename]
sh echo "test" >> [filename]
おまけ : csvをhbkに変換する
シミュレーションではないが、PAW,HBOOKに関する余談。今、以下のような"sample.csv"(実際のところssv)があるとする。
2 0
3 0
4 0
5 0
6 0
7 0
8 0
9 0
(中略)
197 0
198 3
199 153
200 211
201 194
202 232
203 241
204 207
205 216
206 199
207 201
208 229
209 205
210 213
211 175
212 168
(後略)
これをヒストグラムへと変換したいとき、
例えば以下のようなcsv2hbk.fを用意して実行する。
3 0
4 0
5 0
6 0
7 0
8 0
9 0
(中略)
197 0
198 3
199 153
200 211
201 194
202 232
203 241
204 207
205 216
206 199
207 201
208 229
209 205
210 213
211 175
212 168
(後略)
implicit none
c
real H
integer i,ch,nevent
real x(4094)
integer y(4094),sum
common/pawc/H(1000000)
c
call Hlimit(1000000)
c
call Hbook1(1,'channel vs coutns per channel',4094,2.,4095.,0.)
c
sum = 0
open(66,file='sample.csv', status='old')
do ch=1,4094
read(66,*) x(ch),y(ch)
do i=1,y(ch)
call HF1(1,x(ch),1.)
call HF1(2,x(ch),1.)
enddo
sum = sum + y(ch)
enddo
close(66)
c
write(*,*) sum
c
call Hrput(0,'sample.hbk','N')
call HISTDO
c
end
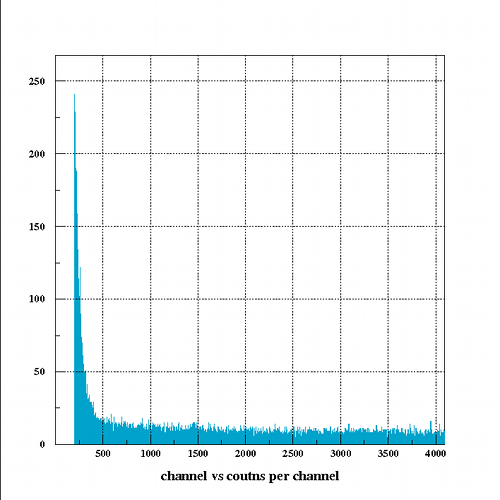
出力されたhbkをPAWで開いてヒストグラムを表示すると例えばこんな感じ。
c
real H
integer i,ch,nevent
real x(4094)
integer y(4094),sum
common/pawc/H(1000000)
c
call Hlimit(1000000)
c
call Hbook1(1,'channel vs coutns per channel',4094,2.,4095.,0.)
c
sum = 0
open(66,file='sample.csv', status='old')
do ch=1,4094
read(66,*) x(ch),y(ch)
do i=1,y(ch)
call HF1(1,x(ch),1.)
call HF1(2,x(ch),1.)
enddo
sum = sum + y(ch)
enddo
close(66)
c
write(*,*) sum
c
call Hrput(0,'sample.hbk','N')
call HISTDO
c
end
補足 : PAWのMemory size control
PAWではCern libraryのZEBLAを使っている。common/pawc/やHlimitで適切な値を入れないとZEBLA関係のエラーが出る。 例えば、
common/pawc/H(40000000)
call Hlimit(2000000)
としてhbkを作って読み込むと、
call Hlimit(2000000)
ANAPAW> fetch hbk/sample.hbk
ZFATAM. !!!!! Going to ZFATAL for EXIT VIA ZTELL.
!!!!! ZFATAL called from ZTELL
called from MZGAR1
called from FZIMTB
Current Store number = 0 (JQDIVI= 2)
1ZEBRA SYSTEM Post-Mortem from ZPOSTM.
/QUEST/
99 2 2139 718 2140 1 76 2
0 32000 -3312609 0 2 -935029248 1777 100531
958 12979 11 68 101 0 1 0
0 0 0 0 0 2 27 0
1 0 0 0 0 0 0 2
63 2 85B 2CE 85C 1 4C 2
0 7D00 FFCD741F 0 2 C8449600 6F1 188B3
3BE 32B3 B 44 65 0 1 0
0 0 0 0 0 2 1B 0
1 0 0 0 0 0 0 2
Last Bank Lifted - COMMON /MZCL/LFW,LS,NIO,ID,NL,NS,ND,IOCH(1)
9986548 9986549 0 RZIN 0 0 1025 2000C hex
9861F4 9861F5 0 4E495A52 0 0 401 2000C
Last Bank analysed - COMMON /MZCN/LFW,LS,NIO,ID,NL,NS,ND
9981178 9981229 0 HDIR 50 8 10
984CFA 984D2D 0 52494448 32 8 A
Map of store 0 /PAWC/
------------------------
Division Number of times
Kind Max-size Garb-coll.
Mode Position used allowed Wiped user auto Pushd Redcd
1 QDIV1 0 1 5001 0 9999988 0 0 0 0 0
2 QDIV2 1 1 9981248 6862660 9999988 0 0 0 0 0
3 KUIP Div 1 1 9986248 167 10000000 0 0 0 0 0
19 system 1 8 9989988 3440 9999988 0 0 1 0 0
20 HIGZ 0 4 9989988 0 10000000 0 0 0 0 0
TRACEQ. In-line trace-back still not available.
DZSNAP --- ZPOSTM OPTIONS : TCWM.
NAME LQSTOR NQSTRU NQREF NQLINK LQMINR LQ2END JQDVLL JQDVSY NQFEND LOW-1 LOW-N HIGH-1 HIGH-N SYST-1 SYST-N END
/PAWC/ ( B0567C8) 1 1 49 164 5001 3 19 5 5001 500031185889981247998654899899879999987
WORKING SPACE ADR(LQ(0)) = B0567C8
1 Z0000000000984D2D 2 0 3 0 4 0 5 0
===== 544 WORDS from 6 to 549 all contain 0
DZSNAP. ----- Store nb. 0 = /PAWC/ Division nb. 1 = QDIV1 --------------------
-- Division contains no banks --
DZSNAP. ----- Store nb. 0 = /PAWC/ Division nb. 2 = QDIV2 --------------------
HCO2. 1 3118591(QDIV2 ) SY/US/IO 0/ 0/ 123 NL/NS/ND 2/ 2/ 1054406 N/U/O/@O 0/ 4173016/ 4173015/ 3118591
HID2. 27 4173016(QDIV2 ) SY/US/IO 2/ 10/2D1D NL/NS/ND 7/ 7/ 17 N/U/O/@O 0/ 9981229/ 4927070/ 4173016
. LINKS 3118591 HCO2
HCO2. 1 4173045(QDIV2 ) SY/US/IO 0/ 0/ 123 NL/NS/ND 2/ 2/ 754006 N/U/O/@O 0/ 4927070/ 4927069/ 4173045
HID2. 26 4927070(QDIV2 ) SY/US/IO 2/ 10/2D1D NL/NS/ND 7/ 7/ 18 N/U/O/@O 4173016/ 9981229/ 5279525/ 4927070
. LINKS 4173045 HCO2
(以下省略)
といったエラーが出てANAPAWが落ちる。ZEBLAを理解してないため適切な値はよく分からないが経験上、
ZFATAM. !!!!! Going to ZFATAL for EXIT VIA ZTELL.
!!!!! ZFATAL called from ZTELL
called from MZGAR1
called from FZIMTB
Current Store number = 0 (JQDIVI= 2)
1ZEBRA SYSTEM Post-Mortem from ZPOSTM.
/QUEST/
99 2 2139 718 2140 1 76 2
0 32000 -3312609 0 2 -935029248 1777 100531
958 12979 11 68 101 0 1 0
0 0 0 0 0 2 27 0
1 0 0 0 0 0 0 2
63 2 85B 2CE 85C 1 4C 2
0 7D00 FFCD741F 0 2 C8449600 6F1 188B3
3BE 32B3 B 44 65 0 1 0
0 0 0 0 0 2 1B 0
1 0 0 0 0 0 0 2
Last Bank Lifted - COMMON /MZCL/LFW,LS,NIO,ID,NL,NS,ND,IOCH(1)
9986548 9986549 0 RZIN 0 0 1025 2000C hex
9861F4 9861F5 0 4E495A52 0 0 401 2000C
Last Bank analysed - COMMON /MZCN/LFW,LS,NIO,ID,NL,NS,ND
9981178 9981229 0 HDIR 50 8 10
984CFA 984D2D 0 52494448 32 8 A
Map of store 0 /PAWC/
------------------------
Division Number of times
Kind Max-size Garb-coll.
Mode Position used allowed Wiped user auto Pushd Redcd
1 QDIV1 0 1 5001 0 9999988 0 0 0 0 0
2 QDIV2 1 1 9981248 6862660 9999988 0 0 0 0 0
3 KUIP Div 1 1 9986248 167 10000000 0 0 0 0 0
19 system 1 8 9989988 3440 9999988 0 0 1 0 0
20 HIGZ 0 4 9989988 0 10000000 0 0 0 0 0
TRACEQ. In-line trace-back still not available.
DZSNAP --- ZPOSTM OPTIONS : TCWM.
NAME LQSTOR NQSTRU NQREF NQLINK LQMINR LQ2END JQDVLL JQDVSY NQFEND LOW-1 LOW-N HIGH-1 HIGH-N SYST-1 SYST-N END
/PAWC/ ( B0567C8) 1 1 49 164 5001 3 19 5 5001 500031185889981247998654899899879999987
WORKING SPACE ADR(LQ(0)) = B0567C8
1 Z0000000000984D2D 2 0 3 0 4 0 5 0
===== 544 WORDS from 6 to 549 all contain 0
DZSNAP. ----- Store nb. 0 = /PAWC/ Division nb. 1 = QDIV1 --------------------
-- Division contains no banks --
DZSNAP. ----- Store nb. 0 = /PAWC/ Division nb. 2 = QDIV2 --------------------
HCO2. 1 3118591(QDIV2 ) SY/US/IO 0/ 0/ 123 NL/NS/ND 2/ 2/ 1054406 N/U/O/@O 0/ 4173016/ 4173015/ 3118591
HID2. 27 4173016(QDIV2 ) SY/US/IO 2/ 10/2D1D NL/NS/ND 7/ 7/ 17 N/U/O/@O 0/ 9981229/ 4927070/ 4173016
. LINKS 3118591 HCO2
HCO2. 1 4173045(QDIV2 ) SY/US/IO 0/ 0/ 123 NL/NS/ND 2/ 2/ 754006 N/U/O/@O 0/ 4927070/ 4927069/ 4173045
HID2. 26 4927070(QDIV2 ) SY/US/IO 2/ 10/2D1D NL/NS/ND 7/ 7/ 18 N/U/O/@O 4173016/ 9981229/ 5279525/ 4927070
. LINKS 4173045 HCO2
(以下省略)
common/pawc/H(10000000)
call Hlimit(1000000)
これくらいなら問題なし。
call Hlimit(1000000)
ちなみにPAWの要求する値は HBOOK Reference Manual > Memory Management and input/output Routines > Memory size control > Space requirements で計算できるようだ。
追記
上記の値で問題ないと思っていたがどうやら強い環境依存性があるようだ。 自分のマシンのANAPAWは落ちなくても同じhbkファイルを他のPCのANAPAWで読み込もうとすると先のようなエラーが出て落ちたりする。 PAWとかのバージョンが違うせいかもしれない。色々未検証。とりあえずANAPAW 2.3.1@geでは経験的にhbkのサイズが45MBを越えるとアウトのような気がする。
ヒストグラムに値が埋まらない
正しくヒストグラムを定義しているにも関わらず、ヒストグラムに値が埋まらず、全て0になる。 このような場合、
call HF1(ID,Value,1.)
のように値を代入する際Valueがrealでない可能性が疑われる。integerだとダメ。
Segmentation faultでハマる
問題なくコンパイルできても実行すると
Segmentation fault
と表示されて詰まることがある。このエラーはメモリ参照に関するミスらしい。いくつか原因があるようだがサブルーチンの引数の数が違ってエラーが出たことがあった。 サブルーチンをいじって引数の数を変えたもののをcallするときの修正漏れでエラー。デバッグに無意味に時間がかかった。
とりあえず端末からsubroutineをまるごと検索、全て修正して回避。
grep subroutine
多次元配列の値を一行で出力する。
例えばdata(i_max,j_max,k_max)という三次元配列があるとき以下のようにすると改行することなく一行で 出力される。
write(6,*) (((data(i,j,k),i = 1, i_max ), j = 1, j_max ), k = 1, k_max )